
Some years ago, it was estimated that out of the one trillion photos taken, billions of them were shared online.
This indicated that images also constituted a huge chunk of the data scraped from different parts of the internet.
And because of the information that these images contain, brands and companies worldwide are also compelled to collect them.
Collecting one image is simple. If the data is publicly available, you could visit the website; find the webpage with the image, right-click on the image and save it.
This may sound straightforward, but this is not the case when you have to do this for thousands or millions of images.
Getting accurate data requires gathering them in large quantities and doing it manually yourself wastes time and energy while also affecting the overall quality of the data while reducing performance and productivity.
This is why tools that automate the process are highly valuable. Puppeteer is one popular tool that can be used not only to scrape multiple images from one website but also multiple images from multiple websites simultaneously.
What Is Scraping?

Source:scrapezone.com
Web scraping can best be explained as the process of collecting large quantities of data from several platforms at once.
The process usually involves using sophisticated tools such as scraping bots and proxies to collect the data and keep the user safe.
The tools also help automate the process making enormous data collection processes less tedious. You can also get in hours or days, the amount of data that would ordinarily take weeks or months to collect when you attempt it manually.
Without the tools for automation, web scraping will be slow and generally ineffective. For instance, you could end up collecting outdated data that might lead to terrible business decisions. And without the other tools like proxies, limitations, and restrictions can stop the process in general.
The data harvest is then stored in a readable and easy-to-use format. The application of the extracted data varies widely and depends on what the company’s needs and goals are.
However, every business that engages in data extraction does so to make more informed business decisions, understand the market and competition and increase their revenue margin.
What Is Puppeteer and Puppeteer Tutorial?

Source:blog.testproject.io
Puppeteer has become a common tool for developers to automate several activities such as web data extraction and website testing. There are several attractions for using Puppeteer, including automation and operating a headless browser.
Automation ensures that tedious tasks are handled mechanically and quickly, which guarantees speed and saves you time and energy.
The ability to operate and work with a headless browser here makes the tool easier to use as it means there is no need to understand the DevTools protocols of the browser or interact with them directly.
Puppeteer is a Node.js-based module or library that provides sophisticated APIs that can be used to operate headless browsers remotely.
At first, the headless browser had to be Chrome, and since the same company owns Puppeteer and Chrome, it is seamless; users can comfortably control headless Chrome with this tool remotely and enjoy the full functionalities of the browser without doing much.
Recently, Puppeteer has been upgraded to work with headless Firefox for similar operations, including visiting multiple websites and extracting their content or testing their performance. This is also done automatically to make the process more efficient. A recent post by Oxylabs goes more in-depth on Puppeteer.
Some of the best attributes and features of Puppeteer that make them so useful include:
1. Automation
Whether it is headless or non-headless Chrome or Firefox, Puppeteer ensures that every task it is engaged in is done automatically.
And since automation is critical in a world filled with data generated every second, such a tool easily becomes a favorite for businesses and individuals alike.
2. Conversion to PDF
Another great thing about Puppeteer is that it can collect data and save it in several formats. One format that has become increasingly useful is the PDF form.
You can now collect any data and store it as a PDF. This makes it easier to save storage space and makes the stored files easier to access. Later, you can convert it into other files. PDF to Word Converter tools are the most commonly used here.
3. Functionality
Another major advantage of using Puppeteer is its versatility in functions. This tool can be used to perform just about any action a regular human could perform on a website.
It can emulate different types of devices that mimic keyboard and mouse actions, and this is why it is an important module for running routine website checks.
How to Scrape For Images with Puppeteer
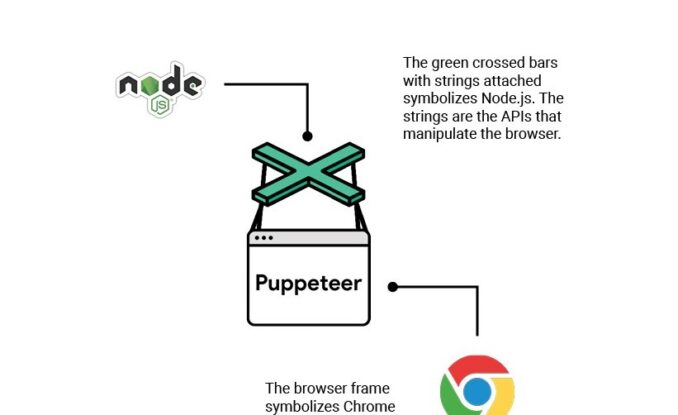
Source:javascript.plainenglish.io
As stated above, Puppeteer can be applied in many areas because of its uniqueness and features.
It can be used for image scraping because it can automatically interact with websites, find the image sources and src values and scrape and save them as a human would. But since it is a machine, it would need to be written and instructed before it can commence work.
But once it is up and running, you can sit back and watch Puppeteer scrape millions of images in record time.
Below are the steps to take to use Puppeteer to scrape image srcs. However, to even know how to work with this library, it may be important to take a quick Puppeteer tutorial.
- First, know the website and page you intend to scrape the images from
- Download and install the Node.js, then install the package manager and create a suitable folder to store all your work
- Enter all the necessary information and additional requirements and dependencies
- Next, open a command line and install the Puppeteer library
- Create a new file for the project, add the target address and launch your tool
- The scraping for image srcs will commence, and the extracted data will be stored in the folder you have created earlier
- Including the attempt, catch statement will help to capture errors and deal with them to prevent them from ruining your entire results
- Finally, Puppeteer will end, and the browser will close once scraping is done
Conclusion
Aside from scraping data in the form of text, you can also use Puppeteer to scrape image src value from multiple sources.
This can be done automatically with a headless Chrome browser to quickly and conveniently collect the images your business needs to use in creating insights.


